Introducing Kubernetes Operators
This chapter covers
-
Introduction to Kubernetes Architecture and key components
-
Limitations with native Kubernetes
-
Extension patterns with Kubernetes
-
Trade-offs when not to use an operator
With the Kubernetes deployment of containerized applications has become more accessible and manageable, you might run a containerized application with persistent data on the Kubernetes cluster. Preventing data loss of your application would require period backups, which help restore the application in case of failures. In most cases, taking periodic backups is a manual process. To automate the backup and restoration of your application, you can automate frequent backups with the help of Kubernetes operators. Kubernetes operators can handle automatic restoration of your applications in case of failure using the backups without human intervention. This is one of the use cases for using the Kubernetes operator. Through the book, we will be looking at many more use cases for Kubernetes operators.
Kubernetes operators provide a consistent way to ship software on Kubernetes with a Site Reliability Engineering (SRE) mindset of automation and ease of scalability. Operators also help to overcome the limitations of out-of-the-box Kubernetes and allow developers to bring new capabilities. Developers can extend the functionality of Kubernetes to build custom solutions for business requirements, including self-healing, automation, and managing stateful applications. Operators reduce human error in the process of deploying and distributing workloads with Kubernetes. Before diving deep into Kubernetes operators, let’s review the basics of the Kubernetes architecture and its underlying components, such as the Control Plane and the Data Plane, the Kubernetes API Server, and the Controllers. Finally, we will go through the pros and cons of extending Kubernetes with the help of operators.
1.1 Introduction to Kubernetes
In an era of rapidly evolving technology in application development, containers stand out as one technology that has significantly impacted. The level of abstraction around application deployment and execution has increased, starting with server virtualization. Containers were the next step for engineering and support teams to abstract applications and their dependencies into an isolated “container.” Containers provide a way to isolate the resources like CPU and memory necessary to run an application and make it portable enough to execute on any virtual or physical server where a container runtime is available. Using Namespaces technology, containers enforce resource segregation on computers. As early as 2002, Namespaces appeared in the Linux kernel and were later used to create containers in 2013.
The container runtime isolates a containerized application from the host system and manages the Namespaces, Linux control groups (Cgroups), and other container resources. Some popular container runtimes are Docker Engine, Podman, Containerd, CRI-O, rkt, LXC/LXD, etc. A container runtime is essential to run, manage, and scale containerized applications.
Container orchestration enables scalability by automating the deployment and management of containers. Additionally, this involves managing container lifecycles, configuring networking and storage, and deploying and scaling containers across multiple hosts. The portability of containers is due to their standardized format defined by Open Containers Initiative, which makes it easy to distribute and store as images. A Container Image is a static file containing code for creating a container on a computer. Registries are online stores that store container images. __Access to these registries is either public or private. For example, some public registries are Docker Hub, Red Hat Quay, Harbor, Amazon ECR, Github Container Registry, Azure Container Registry, and Google Container Registry.
The introduction of container images solved the problem of distribution for applications. However, containers have challenges and issues like any technology, particularly regarding container orchestration. The following are some of the most common challenges and issues with container orchestration:
-
Networking: Multi-container environments can require complex networking, mainly if multiple containers communicate across hosts.
-
Security: Security challenges can arise due to container infrastructure shared by multiple users and possible vulnerabilities in container images.
-
Resource Management: Multiple containers on the same host can consume significant resources.
-
Scheduling: As the number of containers in an environment grows, managing and orchestrating them can become increasingly challenging.
Several popular container orchestration platforms automate tasks around container management, including Kubernetes, Openshift, Hashicorp Nomad, Rancher, Docker Swarm, and Apache Mesos. In this book, we will focus on Kubernetes. The Kubernetes container orchestration tool has become de facto for many companies. Kubernetes is an open-source hosting solution for containers that allows you to run and manage containerized software efficiently—making it easier for developers to ship application software containers from their laptops to the hybrid cloud. The management of containerized applications at scale before Kubernetes was manual and error-prone. System administrators had to manually configure and manage each container and the infrastructure supporting it. As the environment grew more extensive and complex, ensuring consistent application performance became increasingly difficult.
An instance of Kubernetes is called a cluster and is hosted on physical hardware locally or with a cloud provider. A user’s access and control of Kubernetes is done via its REST-based API to create and control resources. A Kubernetes Resource is managed by an endpoint in the Kubernetes API that manages a collection of API objects of a certain kind_._ Users can leverage these API endpoints via YAML files to create and declare the required state of the resource they wish to provision on the cluster. Kubernetes allows organizations to optimize infrastructure utilization by running multiple containers on the same host. The result is a reduction in hardware costs and an increase in resource utilization.
1.1.1 The data plane and the control plane
Kubernetes architecture is designed to be flexible, scalable, and resilient, allowing it to manage scalable application deployments in production environments. Two main components work together to manage containerized applications within Kubernetes: the Control Plane and the Data Plane, as shown in Figure 1.1. The Control Plane is the brain of the operation, and the Data Plane is where execution happens. Containerized applications in Kubernetes are managed and run in conjunction with the control and data planes. The control plane contains and coordinates containers, while the data plane worker nodes run the containerized applications.
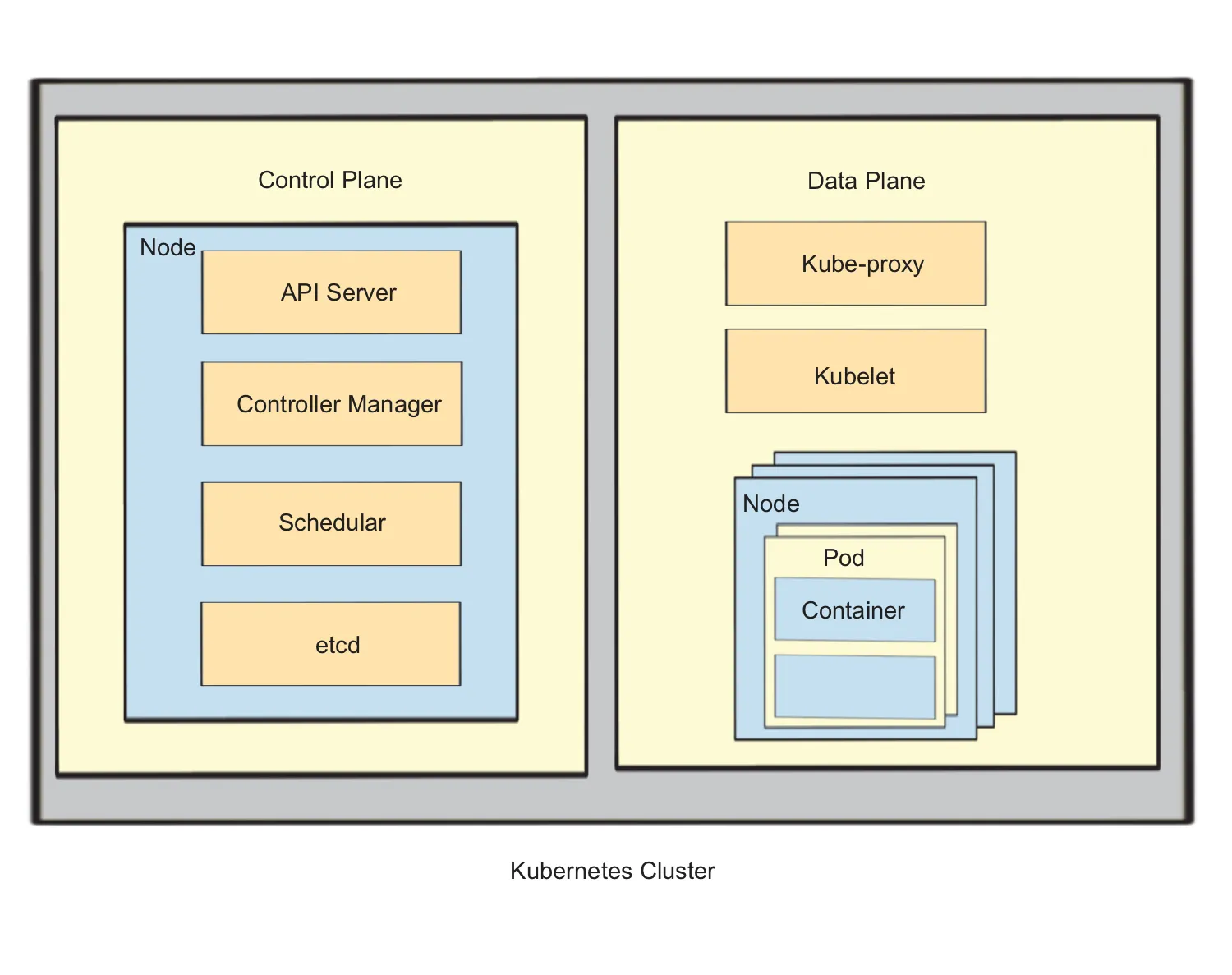
Figure 1.1 Kubernetes Control Plane and Data Plane
The data plane
The Data Plane runs the containers that make up the applications. The Data Plane runs the containerized applications on a physical or virtual machine with an abstraction unit called Nodes. Nodes are worker machines that run containerized applications, also known as worker nodes.
Application workloads run on worker nodes, and containers operate using their resources. A node has an IP address and hostname so the Control Plane can communicate with them. The Control Plane communicates with nodes through APIs to manage and control containers. The Kubernetes cluster allows resizing resources according to the demand of applications by adding or removing nodes as needed. Kubernetes uses the CPU, memory, and storage resources available on a node to schedule and manage container workloads.
NOTE Components of the control plane also run on a node labeled as the master node also known as the control plane node.
Additionally, Kubernetes nodes can be labeled with metadata, allowing fine-grained control over scheduling and workload deployment. For example, a label on a node allows scheduling workload to a specific node based on geographical location or infrastructure capabilities. Each Kubernetes node labeled as a worker node has a set of components for running containers and communicating with the Kubernetes control plane. We can look into Data Plane components and how they interact with the Control Plane, as shown in Figure 1.2.
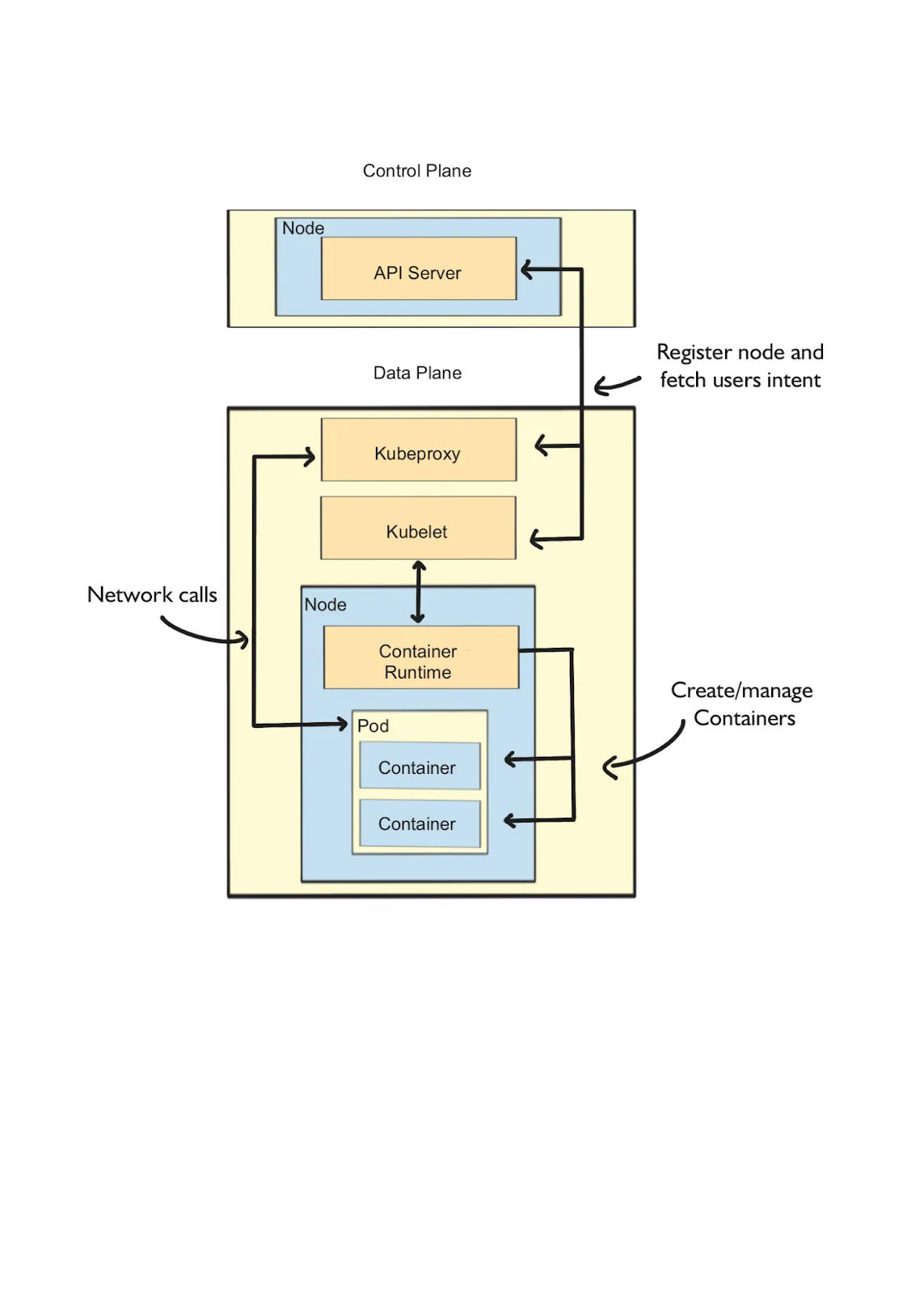
Figure 1.2 Kubernetes Data Plane internals and how the components communicate with Kubernetes API Server
The Data Plane components include:
-
Kubelet: This principal-agent manages containers on a node. The Kubelet handles the start, stop, and monitoring of containers that run on the node; it is one of the core components of the Kubernetes Node.
-
Container runtime: This component is responsible for running and managing containers.
-
Kube-proxy: A network proxy and load balancer manages network traffic to and from each container running on that node. The kube-proxy component manages network connectivity between pods and services within the cluster.
-
Pods: Allows containers to be deployed and managed in Kubernetes clusters simply and easily. Pods consist of tightly coupled containers that share the same network namespace and access the same shared volumes for running processes.
Kubelet registers the node with the Kubernetes API server and maintains the state of Pods in the node with the help of the container runtime engine. Kubelet uses the Container Runtime Interface (CRI) to communicate with container runtimes, such as Docker and Containerd, which allows the node to monitor, start, and stop containers. Each pod can allocate a certain amount of CPU and memory resources to containers, allowing the pod to limit the number of resources consumed by each container. Kubernetes cluster relies heavily on node abstraction to deliver the infrastructure requirements. Containerized applications in Kubernetes are managed and run in conjunction with the control and data planes. The control plane contains and coordinates clusters, while the data plane worker nodes run the containerized applications.
The control plane
The Control Plane is the front entry point for users, where developers can interact and show their desired state, like deploying containerized applications. The control plane is responsible for managing the overall state of a Kubernetes cluster and ensuring that applications are performing optimally. Several components include the API server, etcd, scheduler, and controller manager.
-
API servers provide RESTful APIs that client applications can use to interact with Kubernetes’ control plane.
-
Etcd is a distributed key-value store that serves as the single source of truth for all cluster components, storing configuration data and state.
-
Schedulers place containers on cluster nodes based on resource availability and constraints.
-
The Controller Manager monitors the state of a cluster and takes action to maintain the desired state.
Kubernetes’ control plane functionality relies on the interaction between these components. For example, API servers receive requests from users forwarded to etcd stores for cluster information storage and retrieval. The controller manager and scheduler use the API server to manage different resources and schedule pods onto cluster nodes.
For Kubernetes operator development, we must focus on two main ingredients in the control plane, i.e., API Server and Controller manager. The following section will dive deep into API Server working and core concepts.
1.1.2 Understanding the API Server and Controller Manager
API Server is the main component of the Kubernetes Control Plane, which lets clients interact over the REST API interface. Kubernetes API follows a declarative syntax approach where the user defines the final state of the application in the YAML or JSON file format and applies it through the REST request to the API Server. For example, using the official client kubectl allows a user to perform actions to create or modify the declared state of Kubernetes resources using HTTP protocols, and Kubernetes take care of reaching the declared state by updating the actual state. For example, a user would declare that there should be one instance of the application (declare state), Kubernetes will try to check the actual state of the application i.e no instance running and try to create an instance of application. Whereas, in the case of imperative REST API, a user would request to create one instance of the application, and API will respond the action perform by the user. Next, we examine how the Kubernetes API Server processes a client’s request. Unlike any standard RESTful API, Kubernetes APIs conform to Schema, which is metadata about how the data is structured and what operations are supported. It helps you understand how resources are structured and what types of fields they have in the Kubernetes API Schema.
The Kubernetes API server
Kubernetes API Server is the Control Plane user interface and handles the client’s communication. API Server first processes the request with three main strategies: Authentication, Authorization, and Admission Control, as shown in Figure 1.3. Authentication identifies who can make this request, and authorization verifies what actions are permitted. Admission control verifies the sanity of the request by validation or mutation of the request.
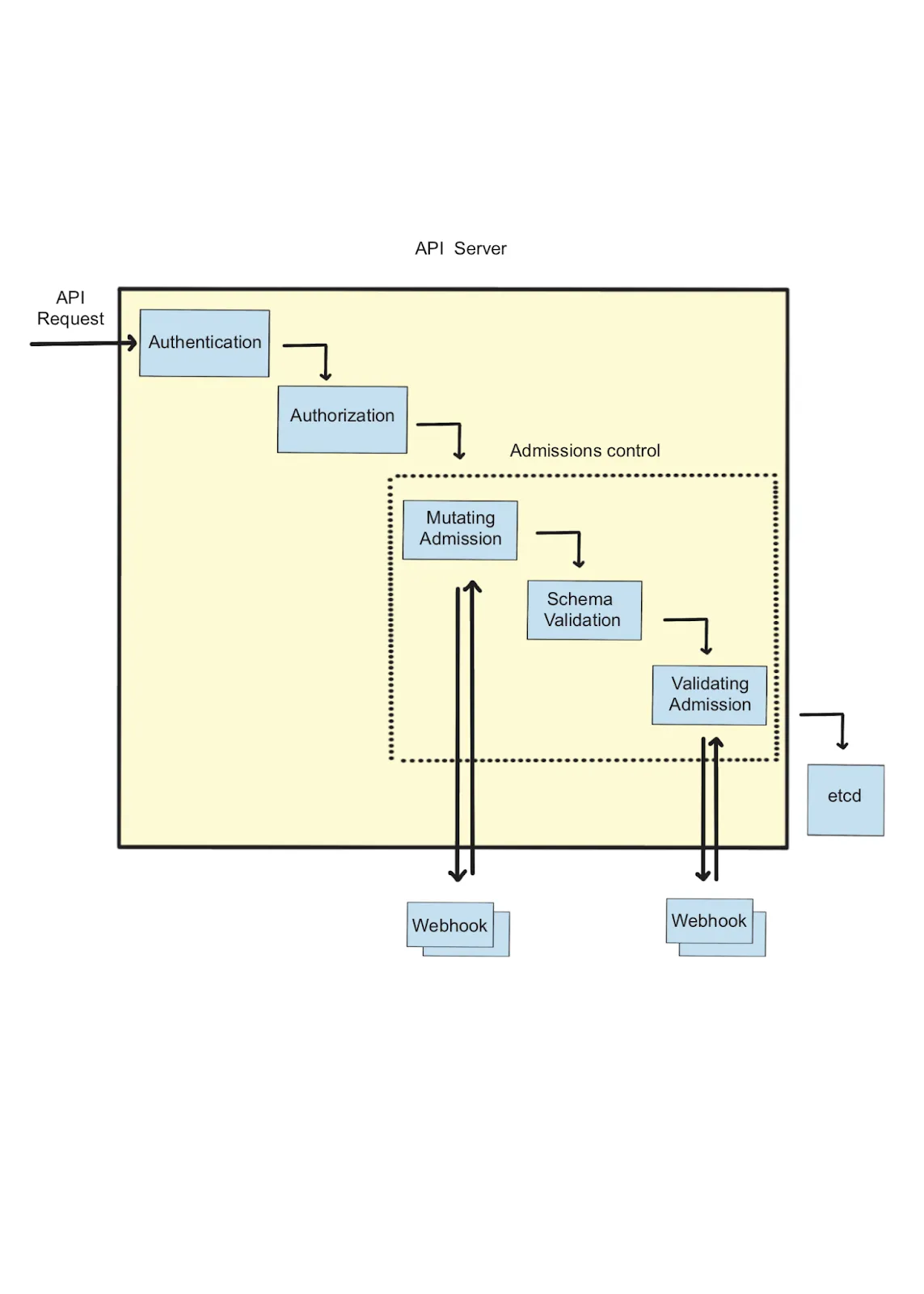
Figure 1.3 - API Server process client request
The Kubernetes API server processes requests from clients by following these steps:
-
Authentication: The API server verifies a user’s authorization before processing a client’s request.
-
Authorization: When the API server has authenticated a user, it checks to see if the user has the permissions required to carry out the requested action. If the user is authorized, it moves to the next stage of the process. Role-based access control (RBAC) drives the authorization decisions as a standard mechanism.
-
Admission Control: This functionality intercepts and modifies requests before they are stored in Etcd, using a WebHook, an HTTP callback from an external extension to the Kubernetes API. Admission controllers are executed in a chain as a flexible mechanism to enforce policy and security requirements.
-
Request Processing: Post admission control, a request is finally get processed with user-desired state results into Kubernetes objects that may be changed, created, or deleted during this process.
-
In the final step, the API server generates a response that includes the request’s status and any relevant data requested by the client.
Controller Manager: the core loop
Controller Manager consists of “Controller” and “Manager.” The controller is a non-terminating loop, and the manager refers to managing various controllers in Kubernetes. Compare to real-life examples: Listening to your favorite song in a loop, conveyor belts at the airport, moving pistons in the Car engine to keep the engine running, etc. In the above examples, each loop is an actions to get the actual state more closely to the desired state: “play the favorite song” is the user ‘s declared state, and music system will try to reach the desire state by playing the song.
Similarly, in case of Kubernetes, Users will declare the end result for the resources, like deploying a containerized application, scaling the replica sets, or deleting a resource. The controller takes care of reaching the user’s desired state. The Kubernetes API server provides information about the cluster’s current state and allows the controller manager to update the cluster as needed. To return the cluster to its desired state, a controller creates or deletes resources by requesting the API server, whenever the cluster is not in the desired state.
The pattern implemented in the Controller follows three qualities:
-
Observe: Events
-
Analyze: Current state vs. Desired State
-
Act: Reconcile
The Controller implements the pattern by observing the resource’s state, analyzing the user’s desired state and acting to achieve the desired state. The Controller Manager contains several controllers responsible for managing a specific aspect of the cluster. The following are some critical controllers managed by the Controller Manager:
-
Deployment Controller - Maintain deployments by scaling down old replica sets and creating new ones on demand.
-
StatefulSet Controller - Provides persistent storage and unique hostnames to stateful applications.
-
DaemonSet Controller - Makes sure that a given pod is running on every cluster node.
-
ReplicaSet Controller - Runs a pod’s desired number of replicas.
-
Job Controller - Manages the completion of a given job.
Ultimately, the Controller Manager ensures that the cluster remains healthy by maintaining the desired state. For example, a web server is deployed on a worker node with one replica set, as shown in Figure 1.4. The developer wants to have three replicas running to handle heavy network traffic. The desired state is three pods, and the current state is one Pod.
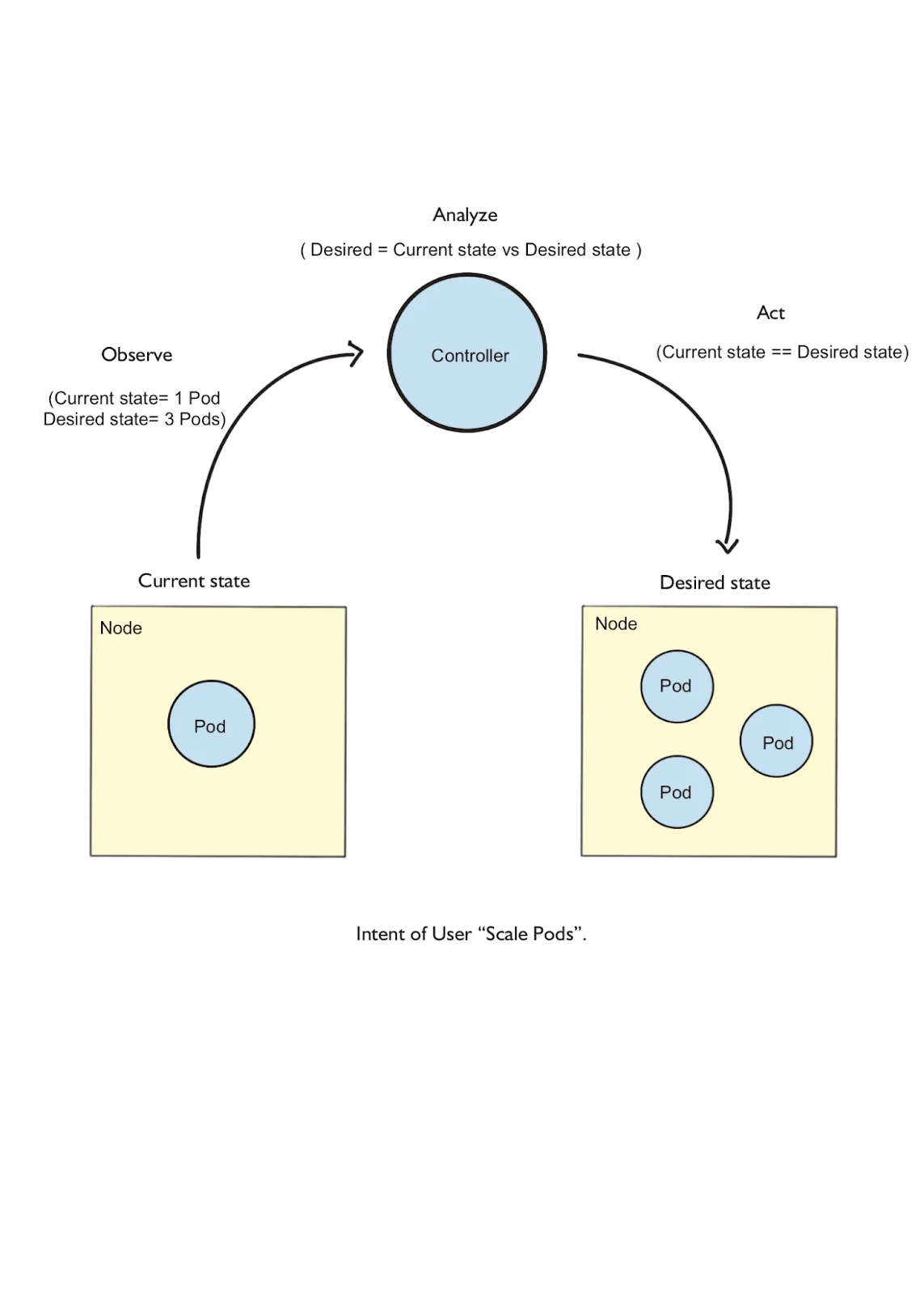
Figure 1.4 Controller scaling Pods from one(current) to three(desired).
The controller manager watches the current state, compares it with the desired state, and starts rolling out Pods to a count of three. We discussed the Controller pattern: Observe, Analyze, and act. In this example, the Controller observes the current Pod state and Analyzes the desired state to scale, i.e., the actual state is 1 replica and the desired state is 3 replicas. Finally, Act to Scale up to three Pods.
So far, we have learned about the core components of the Control plane, i.e., the API Server and the Controller manager, how the API Server processes the user desired state, and the Controller manager helps maintain the state. Next, we can deeply understand the API schema and model concepts.
1.2 Deep dive into Kubernetes API structure and resource
We discussed the Kubernetes API server as it’s the main component for managing the Kubernetes cluster. This section will help solidify the understanding of API schema, how the resources are defined and versioned, and how clients interact with the API server for operating the cluster state. We can start by understanding the HTTP interface without detailing how the API server works internally.
The Kubernetes API follows patterns similar to any RESTful HTTP API. It allows the clients or internal components to interact or modify the state of objects following the standard operations Create, Get, Update, and Delete (CRUD). The client can use the HTTP requests to query and update the Kubernetes Resources. Kubernetes API Server supports standard HTTP Request methods, as shown in Table 1.1.
Table 1.1 Kubernetes Verbs mapping with HTTP Request methods
| Kubernetes Verbs | HTTP Request Methods |
| get, watch, list | GET |
| create | POST |
| patch | PATCH |
| update | PUT |
Figure 1.5 shows how Kubernetes supported verbs can be used to create, delete, update, and modify Pods, as well as other Kubernetes Resources.
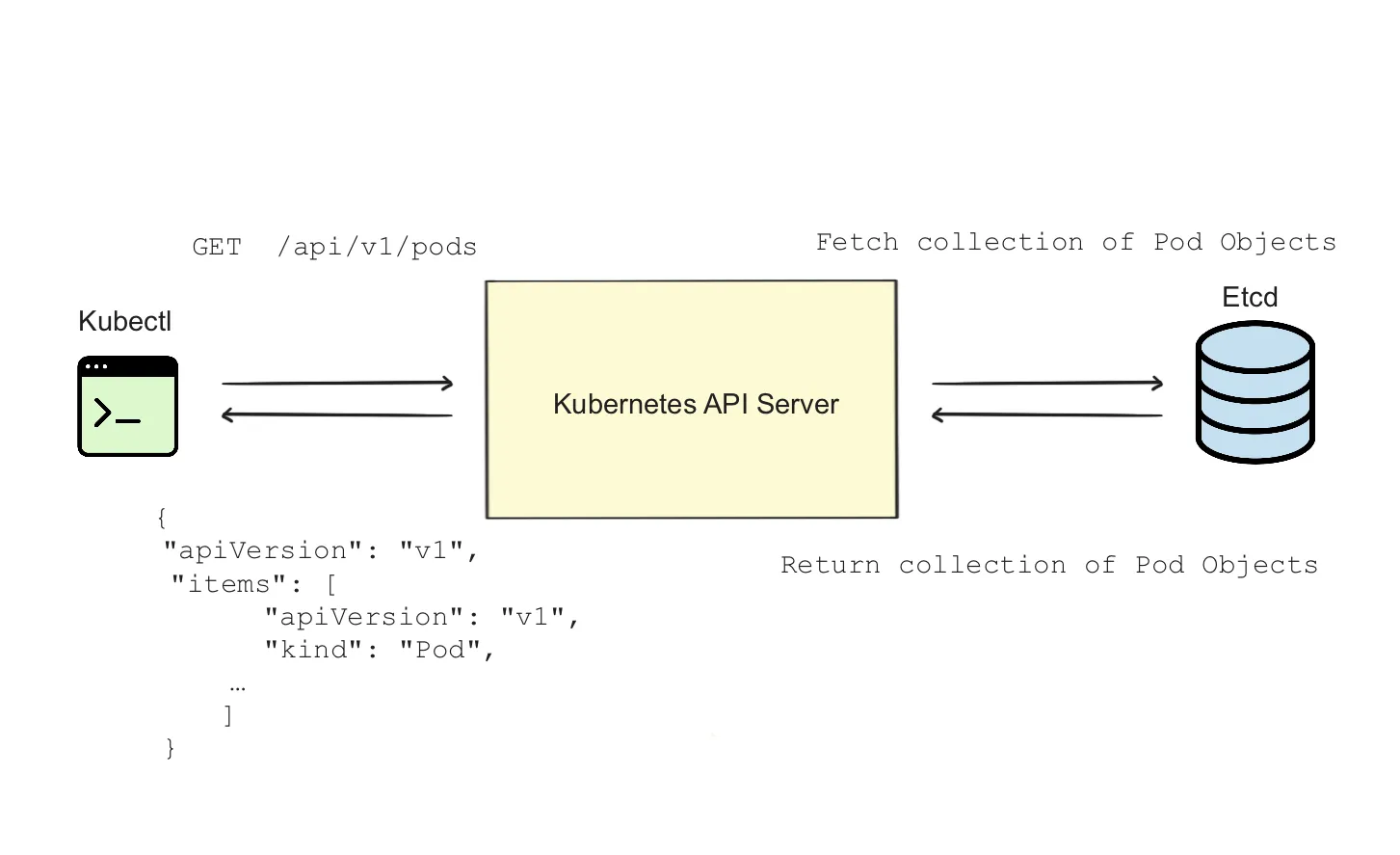
Figure 1.5 Client and Kubernetes API server interaction
A Kubernetes API Server handles the client request, and then the state is persisted in a database called etcd.
1.2.1 Understanding API Terminologies
Let’s go over the essential terms used by the Kubernetes API schema. The API request path URI looks like “/api/v1/pods” for listing all the pods in all namespaces. It represents three components of API schema: Group, Version, and Resource, as shown in Figure 1.5.
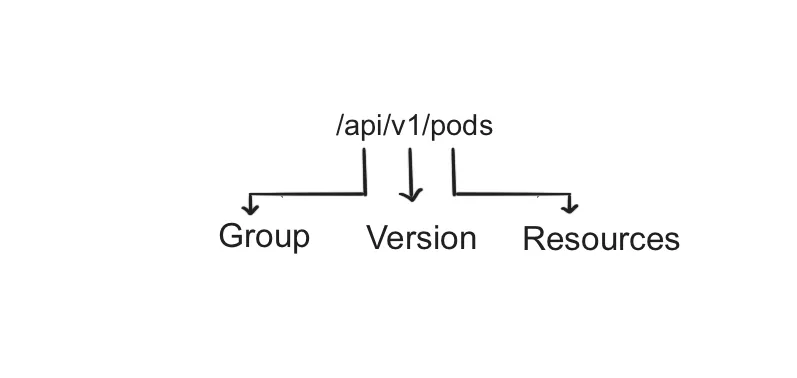
Figure 1.6 Group, Version, and Resources
A Kubernetes resource group allows you to organize resources like pods, services, nodes, etc. A versioning system helps manage attributes for the same Resources and promotes incremental change, allowing developers to make new changes to APIs and release them.
API Group
An API Group is an integral part of the Kubernetes API architecture and provides a flexible and extendable way to manage Kubernetes resources and functions. The Kubernetes API is organized into several groups, each containing a set of resources. API Group or Group allows organizing Resources like Pods, Deployments, Storage, etc. Defining a Group makes it easier to refer to a set of Resources. There are two main groups we can explore to understand it. Two main groups are:
-
Core API (legacy) follows pattern
/api/v1/$Resources -
APIs group follows pattern
/apis/$GROUP/$VERSION/$RESOURCES
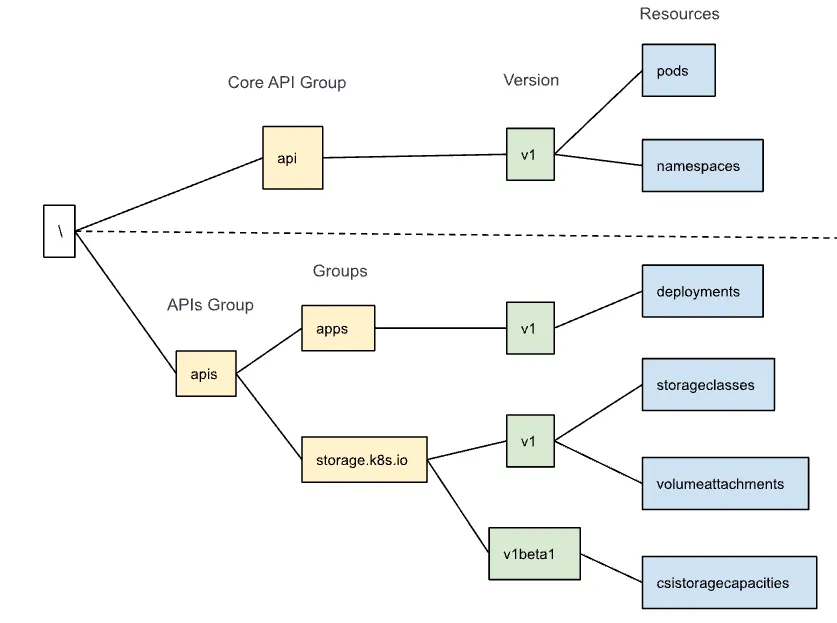
Figure 1.7, representing the Core API and APIs group pattern.
Figure 1.7 Kubernetes API Schema Hierarchy
API Groups also provide other benefits, such as limiting resource access. Kubernetes RBAC authorization allows developers to use the Role and Rolebindings concept to define access policies at the group level. The Role concept consists of rules representing permissions, and Rolebindings comprise the relationship between Role and Subject (for example, a user).
Version
Understanding API versions is essential to working with Kubernetes resources and developing Kubernetes-based applications. API versions define the structure and behavior of pods, deployments, services, and configuration maps. The versioning concept is commonly applied when the fields of a resource are modified. Introducing a new field for an existing API can sometimes require releasing a new version of the API. This can be mitigated by having good default values for new fields. Typically, removing fields from the schema will cause breaking changes and require a new API version and client tools because the contract has changed. Keeping consistent experience and reducing the challenges with API schema restructuring is essential for the developer community.
Kubernetes versioning applies at the API level instead of at the Resource or field level. Versioning presents a firm contract for the consumers. The Kubernetes API supports multiple versions for some resources. This facilitates backward compatibility and introduces new features while supporting older versions. In cases where multiple resource versions are supported, Kubernetes typically uses the newest version compatible with the client’s requested version.
Let’s understand the versioning with an example of Group “storage.k8.io” where two versions are present, “v1” and “v1beta1,” as shown in Figure 1.8.
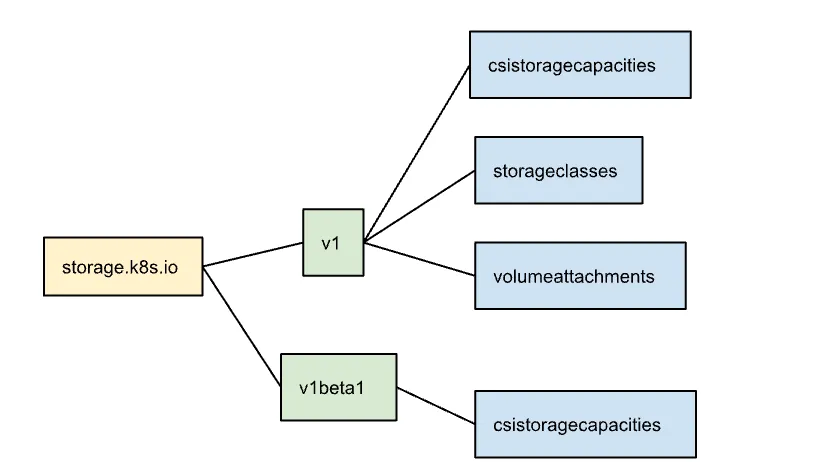
Figure 1.8 API Versioning “v1” and “v1beta1”
Resources available within the apis/storage.k8s.io/v1beta1
- csistoragecapacities
Resources available within the apis/storage.k8s.io/v1
-
csidrivers
-
csinodes
-
csistoragecapacities
-
storageclasses
-
volumeattachments
-
volumeattachments/status
Resource “csistoragecapacities” is available in v1 and v1beta1 versions. Kubernetes API allows accessing the resource with both versions. To ensure that Kubernetes resources are created or modified using the correct schema and behavior, you can specify the API version when creating or altering them.
Resource
A Kubernetes cluster consists of Resources, such as Pods, Volume, and Node, representing containerized applications, storage, or network infrastructure. A Resource Type describes the category of an object you manage in Kubernetes. To manage your workloads, you can interact with the Kubernetes API endpoint or resources, such as “Pods,” “Deployments,” and “ConfigMaps.” Each is a resource type with its own properties and behaviors.
Kubernetes has different scopes for accessing and manipulating resources. There are two main scopes of resources in Kubernetes:
-
Cluster-scoped resources: Cluster-scoped resources include Nodes, PersistentVolumes, and Namespaces, which are accessible from anywhere within the Kubernetes cluster. Cluster-scoped resources are created and managed by cluster administrators. For example, depending on the availability of physical or virtual machines, you can have one or more instances of type Node. By running Pods on a Node, developers can manage their workload independently.
-
Namespaced resources: The Kubernetes cluster contains namespaced resources restricted to a particular Namespace. Namespace resources include pods, services, deployments, configuration maps, and secrets.
The scope also determines the security boundaries of your applications and services. We looked into the Resources and how the structure and behavior are defined. Each Resource is an instance of a Kubernetes Kind, which explains its structure and behavior.
1.2.2 Kinds of Resources
Whereas resources are accessed through the Kubernetes API Server using the Group, Version, and Resource (GVR) or the Group Version Kind (GVK) names in the URI, the entities accepted by and returned from the server (typically in YAML or JSON format) identify their types using the “kind” property. The concept of “kind” in the resource’s body is closely related to the idea of “resource” in the API’s URI structure. Usually, the resource name is simply a lower-case and pluralized transformation of the kind - typically a camel-cased name. The kind field indicates the specific Kubernetes resource type and acts as a directive for the Kubernetes API server on interpreting and handling the object. For instance, if the YAML file has a “Pod” field type, it indicates it describes a pod resource.
Together with the “apiVersion” property in the resource’s body, the kind uniquely identifies the resource type. The “apiVersion” is simply the concatenation of the group and version used for the API server URI.
Each kind defines a schema or structure for resources created of that type. For example, Deployments and Pods each define their own set of fields or properties that may be used when creating or updating those resources. Besides the top-level “kind” and “apiVersion” properties already mentioned, commonly used properties for built-in Kubernetes types include “metadata,” “spec,” and “status.” The “metadata” property includes its own properties that specify things like namespace, annotations, and labels that apply to the resource. A resource’s “spec” property defines the desired state - things like the number of replicas for a Deployment or the containers to run in a Pod. Finally, the “status” is used to store the actual state of the resource - how many replicas are ready or the status of the individual containers. Typically, the user modifies the “spec” to set the desired state for the resource, while the controller normally updates the “status.”
1.3 Overcoming the limitations of Kubernetes with operators
Kubernetes is a powerful and flexible platform. However, out of the box, Kubernetes has limitations. Kubernetes has native resources for managing stateful applications, like StatefulSets. StatefulSets is a Kubernetes workload object designed to manage stateful applications with stable network identities, ordered deployment, and persistent storage. StatefulSets have their limitations, and managing stateful applications is a good example of how operators can help us improve on this. Some of the common challenges with stateful applications like databases, messaging queues, and distributed applications with storage are:
-
Backup and Recovery: A stateful application can be challenging to backup and recover in Kubernetes.
-
Application Scaling up and down: Scaling up stateful applications is relatively straightforward, but scaling down requires careful consideration. Data loss or corruption could occur when scaling down.
-
Persistent Storage: StatefulSet can pose a challenge when it comes to managing persistent storage. A StatefulSet can be disrupted by creating and deleting persistent volumes, resulting in downtime.
-
Network challenges: Network management tools are available in Kubernetes, but they are unsuitable for all stateful applications.
-
Data consistency: In Kubernetes, there are no built-in mechanisms for ensuring data consistency, so managing data consistency falls to the application itself, which can be challenging, especially in a distributed environment.
-
Node Failures: Whenever a Kubernetes node fails, stateful application data can be lost.
-
High Availability: Ensuring high availability in a Kubernetes environment is problematic, especially when cluster-wide outages or node-level failures occur.
1.3.1 Extend Kubernetes with operators.
Depending on the organization, Kubernetes may not support all requirements. In such cases, extending Kubernetes to meet those requirements is possible. Kubernetes supports various extension patterns to add customization. Kubernetes operator is one method to extend the Kubernetes platform and enhance capabilities.
Kubernetes operators can make Kubernetes more reliable and resilient by automating the management of application workloads. Operators of Kubernetes can help overcome the following limitations:
-
Automation with application management**:** operators can easily automate the deployment of large-scale applications, which require multiple Kubernetes resources deployment and provide a consistent way to distribute.
-
Stateful workload management**:** Kubernetes operators can automate the management of stateful workloads and tasks such as automated backups, self-recovery, and optimized configuration management.
-
Automate application updates: operators can handle automatic version updates tasks such as version control, rolling updates, and conflict resolution.
-
Self-Healing and handling failures: Kubernetes operators can monitor the health of their applications and automatically address problems and prevent downtime, improving their reliability and reducing downtime risks.
Kubernetes operators enable organizations to overcome the limitations discussed earlier and take full advantage of the platform’s capabilities.
The Kubernetes platform includes a wealth of extension mechanisms that allow you to customize the platform to meet specific requirements and use cases. These mechanisms can be leveraged to build custom solutions that extend Kubernetes’ power and flexibility while also leveraging its strong foundation and ecosystem at the same time. The following are some methods that can be used to extend Kubernetes:
-
Kubernetes Operator: A Kubernetes operator is a higher-level abstraction over custom controllers that automates the management of complex applications in Kubernetes. It is a combination of Custom Resource Definitions (CRDs) and Custom Controller.
-
Custom Resource Definitions (CRDs): allow users to define their own resources in Kubernetes.
-
Custom Controllers: It is a way of defining your own logic that is then applied to resources that you are managing
-
-
API Aggregation: A Kubernetes feature called API Aggregation allows users to combine multiple API servers into a single API.
-
Custom Admission Controllers: Custom validation rules can be added to admission controllers to add custom validation rules and modify requests before Kubernetes API servers process them.
Using these patterns, users of Kubernetes can extend the platform to meet their specific requirements and build robust and complex applications on top of it. We will investigate Kubernetes Operators in-depth, but let’s first understand the custom resources.
1.3.2 Custom Resource Definitions
The Kubernetes API provides the ability for you to define new custom resources and their schemas, as well as essentially extend the Kubernetes API. You can use Custom Resource Definitions (CRDs) to determine custom objects, services, and applications specific to your business needs. Defining a custom resource will follow the same declarative approach as Kubernetes APIs.
Using Custom Resource Definitions (CRDs), Kubernetes adds resources to its API that are unique to your application or use case, making it easier for you to take advantage of it. Defining a custom resource for your application will require representing a CRD in Kubernetes. As with any other native Kubernetes resource, CRD represents the metadata and schema for your Kubernetes application in the YAML file format. Once you deploy the CRD, any desired number of instances for the custom type can be requested, known as Custom Resource (CR), depending on the infrastructure limitations.
For example, suppose you have a product named “MyApps” with components like a front-end application, a backend for the front-end application, and a relational database. Deploying the to Kubernetes will require 3 YAML files for each element. To consume this product, each consumer must configure various places in YAML before deploying to Kubernetes, such as database connection strings, services host and port, number of replica sets, etc. Deploying all the components and managing the database backups will require manual operation.
With the help of CRD and Kubernetes operator, the configuration of the product “MyApps” can be simplified from 3 YAML files to 1 CRD YAML, which will take care of all the input parameters required by all product elements, and the Operator will handle the product deployment.
if you want to define a custom resource, say with the name: “MyApps,” version “v1,” and group `example.com.` The API URI will look like this: “/apis/example.com/v1”. Like any other Kubernetes API end-point, you can interact using the kubectl command-line tool. CRD will let you define the parameter required for running all three “MyApps” product components.
Now, we have defined the “MyApps” as a CRD definition, which is added as part of the Kubernetes API Server. We can create any number of instances per Kubernetes’ requirements and limits. For example, as shown in Figure 1.9, instances of CRD are created in namespace A and namespace B.
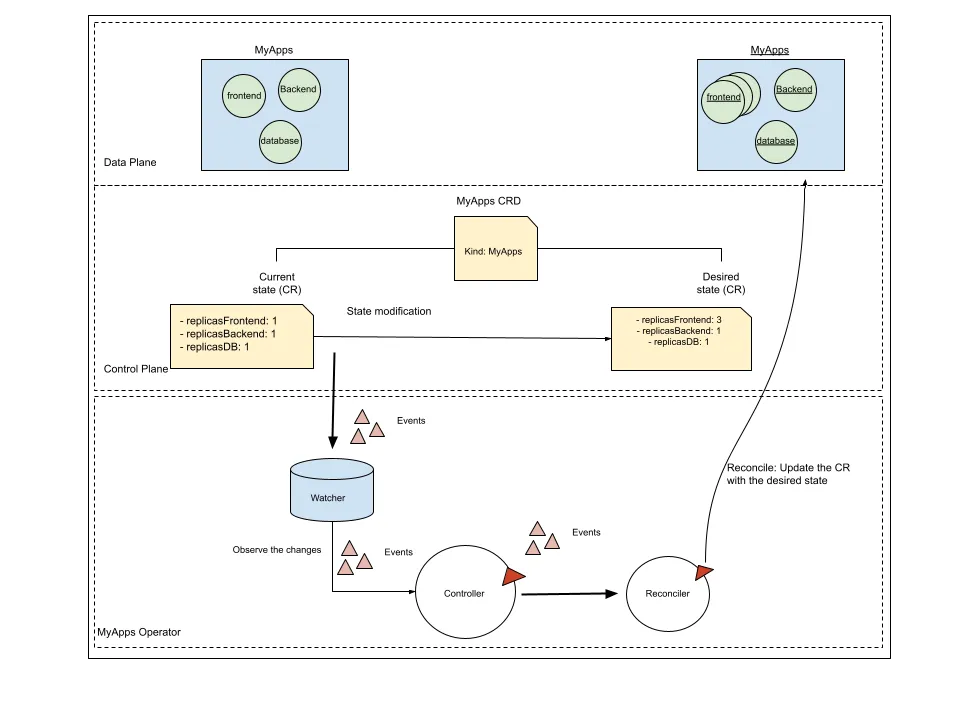
Figure 1.9. Instances of Custom Resource Definitions in Namespace A and B
For example, If you want, we can create an instance of type: “MyApps” with the name of your choice with fields defined in the CRD schema. We can create an instance with the term “sample-app” in the namespace “default”. Once you have created instances of your custom resource, we can use Kubernetes to manage, monitor, and deploy your custom resources like any other native resource.
The custom API allowed us to define an instance of the custom resource type. It only creates a resource in the Control Plane, but creating a workload development or performing a custom operation in the data plane will require adding a custom controller for the custom resource. Hence, it will require defining an Operator.
1.3.3 Kubernetes Operators
Kubernetes Operators use a combination of Custom Resources, also known as operands, and Custom Controllers to automate and manage workloads. Custom Resources (CR) define the desired state of the application, while Custom Controllers reconcile the current state with the desired state. The Kubernetes operator follows three qualities like a human operator:
-
Observe: Watch events for the custom resources
-
Analyze: current state vs. the desired state of the custom resources
-
Act: Reconcile
For example, a human telephone operator would observe the request from the calls, analyze the inquiries & act by doing what’s required. Differentiating factor for a native Kubernetes controller and an operator is the Resource type. The operator works on a custom type and manages them.
Custom Controller observes the events for Custom Resources, for example, MyApps Container Pending, MyApps Container Started, etc. Analyze a container’s current state: “Pending” or “Failed.” Act on the conditions like if the current state is “Failed” for a container; desired logic can be trying to make the container in the Running form. With the Operator’s help, we can manage outside resources such as MyApps in Kubernetes as native resources.
The operator pattern lays a strong foundation for extending Kubernetes without breaking the platform. Let developers implement the operator in their preferred languages, such as Golang, Java, Python, etc. It makes adaptation convenient and maintainable for the system administrators. Once a Kubernetes operator gets up & running, It doesn’t require re-inventing new tools for managing or performing system administration operations. All existing knowledge of the Kubernetes platform is all that you need. That makes this pattern effective & sustainable across a wide range of use cases.
Let’s continue with our example for defining the custom resources definition: “MyApps.” Suppose when we request an instance of the “MyApps” custom resource. It will trigger a deployment of a custom application workload, and the number of pods will depend on the Spec field “replicasFrontend, replicasBackend and replicasDB” specified in the “MyApps” CRD schema. We will add a custom controller that will watch the CR and create the deployment of a custom application, as shown in Figure 1.10.
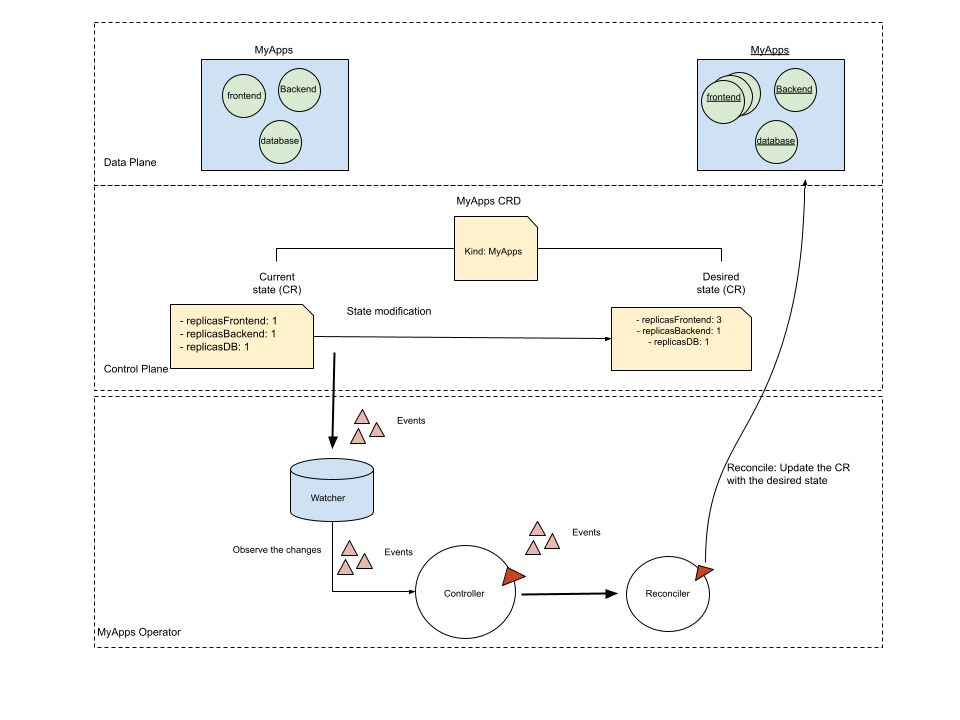
Figure 1.10 Kubernetes Operator: Watching the event for changes in the custom resource and reconciling the changes.
In the case of the Myapps example, the operator would deploy a frontend, backend, and database based on the input values from the spec fields replicasFrontend:1, replicasBackend:1 and replicasDB:1. If a developers wants to scale the frontend application, declares an update to the replicasFrontend spec field from 1 to 3 as input to the CR. The operators would create 3 instances of all frontend application and keep the single instance of backend and database running with no changes. In this scenario, the operator is handling the complexity of managing three dependent elements, making it easy for users to consume the product.
Utilizing the Kubernetes client libraries, the operator requests the Kubernetes API server and monitors changes to the custom resource. The Operator ensures that the application’s desired state is maintained when a change is detected.
A deployment for a custom application is created by the Operator when it detects a new MyApps object. The Operator creates the deployment using the Kubernetes client libraries to request API Server.
Typically, the Operator queries the Kubernetes API to check the deployment status of pods after creating the deployment.
If the “MyApps” custom resource object is updated, the Operator updates the deployment to reflect the new state of the application. In most cases, this involves scaling the deployment or updating the container image.
In case if you want to remove the instance CR created, the Operator deletes the deployment along with any associated resources to ensure the application is fully removed.
As a general rule, Kubernetes Operators who watch a custom resource and deploy a custom application follow a multi-step workflow that involves defining the CRD, creating an operator, monitoring for changes, creating a deployment, monitoring the application, handling updates, and handling deletions.
Kubernetes Operator helps enterprises manage distributed workloads, stateful applications, and services by automating management and overcoming Kubernetes limitations.
1.3.4 Tradeoffs: when operators aren’t needed
For managing applications and automation on Kubernetes, Kubernetes operators can be helpful, but there are also times when writing an operator can create overhead. Here are some tradeoffs to consider:
Security & Privileges Escalation
Typically, operators are deployed as Kubernetes deployments or StatefulSets within clusters and run in their pods. By default, these pods have the same privileges as any other pod in the cluster. In order to create new Kubernetes objects or modify existing ones, however, Operators may require additional permissions.For the Operator pod, you can create a Kubernetes service account and grant it the necessary roles and permissions. As a result, the Operator is able to perform its tasks without giving unnecessary privileges to other pods or users.
When operators don’t adhere to security good practices or have overly permissive access to Kubernetes resources, security risks can be introduced to an application. Although the Operator has a number of permissions, it is crucial to carefully examine them, as attackers might abuse these permissions. Using the Operator pod’s privileges, an attacker could compromise the cluster’s security if they gained control.
To avoid these risks, it’s important to carefully consider whether an operator is necessary for a specific application, and to make sure that it is properly configured and maintained. For an application to be secure and simple, operators need to be reviewed and audited regularly to ensure they are not creating unnecessary complexity or security risks.
Workload Relevance & Troubleshooting
If you have a simple application and can manage it with Kubernetes resources such as Deployments, Services, and ConfigMaps, you may not need an operator. It may not be necessary to have an operator if your application does not require dynamic configuration or scaling. It can be challenging to troubleshoot and debug Operators. Operators can add another layer of complexity to an application, making it more difficult to solve problems. This is because Operators may interact with multiple Kubernetes resources and components, making it difficult to pinpoint the source of any issues or errors.
It is possible to find pre-built tools or solutions that can accomplish the same goals without the need for an Operator. Some cloud providers offer managed Kubernetes services with prebuilt tools to manage databases or other complex infrastructure.
Resource Management & Cost Overhead
A Kubernetes Operator can add additional overhead to resource utilization, including CPU, memory, and storage. In addition to continuously monitoring changes in the cluster, Operators may be required to perform complex tasks such as creating Kubernetes resources or modifying them.
Operators continuously monitor custom resources, generating more API calls than other tools, contributing to cluster load since they require deployments. Operators can use resources excessively, monitoring and managing resources even when they aren’t needed to the point of increasing costs and decreasing performance. An Operator may not be the best choice for a cluster with limited resources. Operators have an internal caching mechanism to minimize the impact or the number of API requests, but still are costly and significantly increase the cluster load against the API server.
Multi-cluster operating requires special skills and deep knowledge of Kubernetes APIs for managing Operators, especially when you use Kubernetes Operators. A learning curve is required for both developers and system administrators. Developers must learn the Kubernetes API and the Operator development frameworks or libraries, while system administrators must learn how to use the Operator and troubleshoot problems.
In summary, while Kubernetes Operators can be a robust tool for managing workload applications and infrastructure, they require a certain level of expertise and may not be the best choice for simpler use cases. When evaluating whether to use an Operator or another tool, it’s important to consider factors such as complexity, learning curve, overhead, scope, and availability of pre-built tools.
1.4 Summary
-
The Kubernetes architecture is divided into a control plane and a data plane. The control plane can be thought of as the brain and the data plane carries application workloads. Users interact with Kubernetes via the control plane component known as the API Server.
-
Each type of resource in Kubernetes is managed by a process called a controller. Controllers take care of ensuring that resources are operating in the desired state.
-
Interaction with the API Server is done using a conventional REST interface. Resource URIs are structured hierarchically with a group, version, and resource type in the path.
-
Similar to the resource URIs, each type of resource in Kubernetes is defined by a Kind and an API version. This allows for each resource to be uniquely identified, grouped by functionality, and versioned to support new features or functionality.
-
Although powerful out-of-the-box, Kubernetes has limitations. These are particularly apparent when dealing with stateful applications that require advanced insight to manage things like data persistence, failover, and high availability.
-
Operators allow application developers to extend the default Kubernetes API by defining custom kinds of resources and controllers (programs) to handle them. An operator can contain the application-specific know-how to overcome the limitations inherent in Kubernetes as it relates to a particular application or system.