Getting to know operators
This chapter covers
-
An overview of some commonly used operators
-
An in-depth look at an existing operator
-
Writing a simple operator to solve a real-world problem
-
Managing custom resources with a custom controller and reconciler
In this chapter, we will delve deeper into operators to discuss the growth of the operator pattern and some common existing operators and their use cases. We will also take a closer look at one of the many available operators to illustrate the power of the operator pattern.
We will go into writing a simple operator for a real-world scenario to cover concepts like defining Custom Resources and the schema specification based on your business requirements. Similar to controllers for native Kubernetes resources, we will look into creating a custom controller to manage the newly added Custom Resource type with the help of operator tools. We will show how to get the operator up and running on a local development Kubernetes cluster to bring concepts together.
As a demonstration, we will write an operator that leverages Git for a continuous delivery approach to deploying a cloud-native application.
2.1 Existing operators
Custom Resource Definitions (CRD) introduce new kinds to the Kubernetes API. When the CRD creates new kinds, operators are code running in containers that act upon them. The final element is the Custom Resource (CR), an instance of one of the new kinds the operator is watching for. Operators can watch for multiple CR kinds. To summarize:
-
A Custom Resource Definition defines new API Kinds.
-
Operators watch and act upon those new Kinds.
-
A Custom Resource is an instance of the new Kind that the operator is watching for.
Figure 2.1 shows the logic of these interactions.
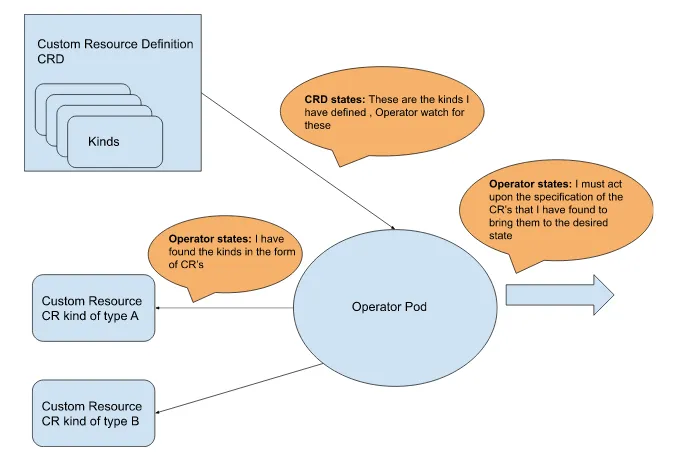
Figure 2.1 The Operator Pattern
As operators are code, we can add whatever functionality we wish to extend the Kubernetes API. When an operator is installed, a CRD is also installed and ready for use. The flow is that a user creates a CR to show the desired intent, which can be a YAML or a JSON file. With kubectl, the Kubernetes command-line tool, you can upload the CR file to a Kubernetes cluster. Figure 2.1 shows that the operator detects the CR while watching for its kind. As operators are extensible, they can be programmed to access client libraries for APIs beyond the Kubernetes API. As an example of this flexibility, AWS Controllers for Kubernetes is a project with multiple operators that can provision AWS resources in the AWS cloud using the AWS client libraries.
Operators are rapidly becoming the default installation method for software in Kubernetes due to their ability to extend Kubernetes, codify installation, and upgrade operations. This is because the installations are relatively painless as operators remove much of the overhead of getting a product up and running in Kubernetes. Generally, a user must create a YAML file for the CR, and the operator takes care of the rest. In some cases, installing the operator is all a user has to do, as operators can create their own CRs. Looking at the operator catalogs, which are online repositories of operators that some providers have available, we estimate that about 750 operators are available. The true number could be multiples of this, as not all operators have a presence in all providers’ catalogs. It would be futile to try to list them all or know all the possible use cases, but let’s discuss some of the common ones.
2.1.1 Use case: database operators
Currently, numerous Database operators are available. A few examples include Redis Enterprise Operator, MongoDB Enterprise Operator, and MariaDB Operator. In Chapter 1, we discussed StatefulSets and how they are primarily helpful in establishing a persistent relationship between a container and another Kubernetes resource.
Using Stateful Sets and Persistent Volumes helps ensure data integrity. However, human intervention is needed to manage database administration tasks. In the case of a database failover, administrator tasks such as recovering database members and re-joining the highly available architecture can be done by the operator. Other administration tasks, such as automated backups and database upgrades, can also be handled within Kubernetes. Operators can automate such critical tasks as
-
Automated deployments that adhere to strict consistency and don’t have a single point of failure
-
Simplified scaling with the ability to add or remove members of a Cluster or Replica Set by changing the size parameter
-
Fully automated backups and restores
-
Database engine version control and upgrade functionality
These database operators generally leverage StatefulSets and have options for installing databases with a persistent volume claim and persistent volumes on a Kubernetes cluster, as shown in Figure 2.2. Some offer persistence off-cluster as well.
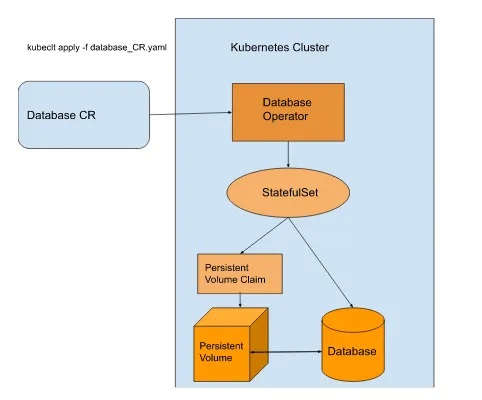
Figure 2.2 Database creation flow
In Figure 2.2, a user creates a CR of the database kind, and the database operator pod acts upon the kind by creating a StatefulSet. As discussed in Chapter 1, Statefulsets are an abstraction in Kubernetes for managing stateful applications. The Statefulset creates the Persistent Volume, Persistent Volume Claim, and Database pod. The StatefulSet ties the database pod to the Persistent Volume Claim with a persistent unique identifier. In Kubernetes, individual pods are susceptible to failure. The database pod with ephemeral storage can be restarted or moved safely, and it will automatically reconnect to the Persistent Volume using the unique identifier and the Persistent Volume Claim. The real benefit is that the end user doesn’t need to know about configuring StatefulSets and Persistent Volume Claims and Persistent Volumes. The operator handles all this Kubernetes configuration for them. Users don’t need deep Kubernetes knowledge to use a database with their applications.
Some operators will install multiple different kinds of databases on various Cloud providers. The Crossplane Operator is an extensible operator with providers that can provision Databases and cloud infrastructure on Amazon AWS, Google Cloud, and Microsoft Azure. Red Hat’s Cloud Resources Operator has installation strategies to install Postgres, Redis, and S3-like storage on the Amazon AWS and Google GCP clusters. These operators are pretty similar in function. They leverage the freely available APIs of cloud providers to provision resources on their infrastructure.
2.1.2 Use case: monitoring operator
Installation of monitoring tools is also a common use case for operators. Take the Prometheus Operator and the Grafana Operator, to name two. These will generally install monitoring software on a Kubernetes cluster. Prometheus is a monitoring tool that can scrape metrics from services, pods, and ingress in Kubernetes. Prometheus’s query language can then manipulate these metrics to customize what you want to monitor about your Kubernetes cluster. In addition, Prometheus also installs an alert manager, which triggers alerts based on thresholds. A schematic view of the Prometheus Operator is shown in Figure 2.3. You can create a Prometheus CR of kind Prometheus, which, in turn, will cause the Prometheus operator to create a Prometheus Statefulset and an AlertManger Statefulset based on the specifications of the Prometheus CR. These Statefulsets then create the respective pods, persistent volume claims, and persistent volumes for both Prometheus and AlertManager. Along with the installation, CR Prometheus has several other CRDs available to configure alerts and monitors.
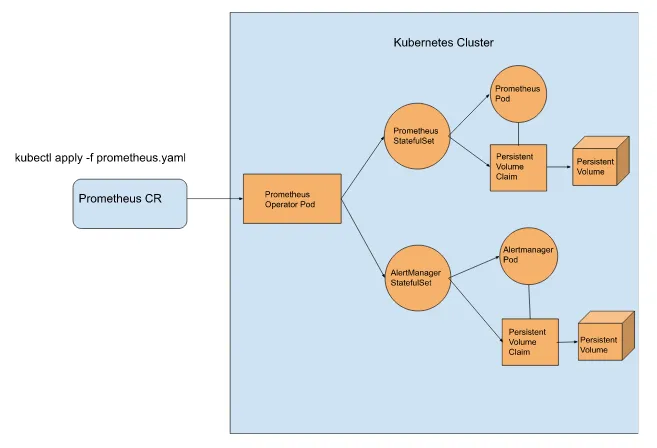
Figure 2.3 What happens when an Observability CR is created
2.1.3 More advanced operator use cases
An excellent example of an advanced use case is the 3scale Operator, an API management solution. What we mean by API management is that you can add your REST API to this tool to handle Authentication, Rate Limits, Metrics, Analytics, API documentation, and billing. The 3scale Operator leverages the operator pattern to create resources within the tool by linking specific Custom Resources to API endpoints in 3scale.
The 3scale operator’s installation CRD is a kind of APIManager. Creating an instance of the APIManager kind with a CR will create 3scale’s GUI. As part of this installation, the operator will create 12 deployments and about 30 Pods with sidecar containers, and It will provision its databases with persistent volume claims and persistent volumes. It provides MySQL, Postgres, and two Redis instances on a cluster if that is your desired configuration. The 3scale Operator also has extra kinds that it watches. These CRs, when created, will create resources in the 3scale GUI.
In Listing 2.1 is a sample 3scale ApiManger CR, which only has the basic setup for running 3scale GUI on a Kubernetes cluster. Only a little configuration is required to deploy a complex app. It has two fields in the specification: one is a secretname for some credentials for an s3 bucket, which is an AWS volume, and the second is the wildcardDomain, which is a domain used for resource resolution within the tool.
Listing 2.1 Sample APIManager CR
$ cat 3scale_CR.yaml---apiVersion: apps.3scale.net/v1alpha1kind: APIManagermetadata: name: apimanager namespace: 3scale-testspec: system: fileStorage: simpleStorageService: configurationSecretRef: name: secretname wildcardDomain: some.domain.comEOFWith this information, the 3scale Operator will trigger and create deployment configurations. These, in turn, will create Pods, secrets, config maps, deployments, services, routes, and persistent volumes for the databases, as shown at a high level in Figure 2.4. Finally, it makes sure all these components can communicate with each other.
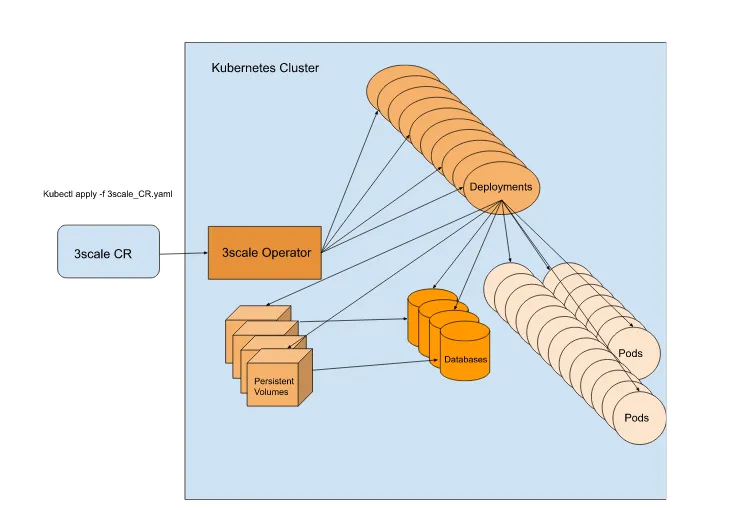
Figure 2.4 Overview of the objects created by the 3scale Operator
2.2 Deep dive: the cloud resources operator
We discussed the Red Hat Cloud Resources Operator previously. An operator can take credentials as a secret to a Cloud provider like Amazon AWS or Google GCP and provision Postgres, Redis, and S3 buckets and their infrastructure on the cloud provider. The Cloud Resource Operator extends the Kubernetes API to provision resources outside of a Kubernetes cluster beyond the default capabilities of Kubernetes. When deleting a CR, the operator will delete the resources provided on the cloud.
This operator’s primary function is to provision databases for other applications. It will create the database on whatever cloud provider or Kubernetes cluster the developer wishes and create a secret with the credentials and access details to that database. It will tag the resources on the cloud provider for identification purposes. It can scrape metrics from AWS Cloudwatch and Google Cloud Monitoring and expose them on the Kubernetes cluster so monitoring tools can consume them on the cluster. It can patch and upgrade these database instances in the cloud. In addition, it can trigger backup snapshots on the remote cloud provider. As a result of accessing the public APIs from the cloud providers through the operator, the operator builds the functionality.
The operator is written in Golang and leverages the client libraries in AWS with aws-sdk-go and Google with their Go Cloud Client Libraries for accessing and provisioning their cloud resources. It can provide Postgres and Redis on a cluster as an extra feature using the Kubernetes API and available containers. In Figure 2.5, we use pre-created Custom Resources files with the kubectl command to trigger database creation on the cluster and cloud providers like Amazon AWS and Google GCP. The Cloud Resources Operator pod picks up these CR kinds and then acts upon their specifications to provision the databases. When finished provisioning, the operator will get the database credentials and create a secret from the credentials. Applications can then access databases using these secrets.
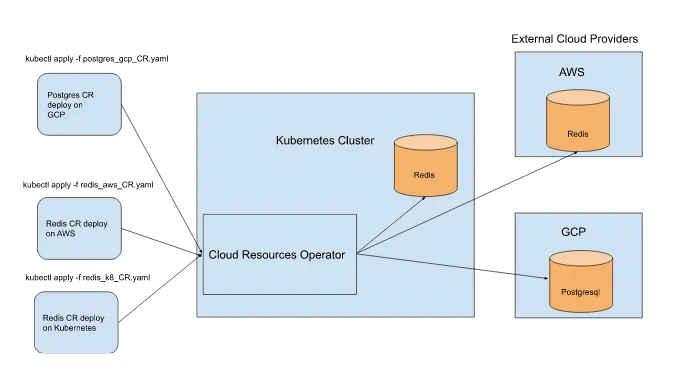
Figure 2.5 Redis and Postgres CR’s triggering the creation of databases on and off the cluster
Table 2.1 Custom Resources and what they can provision
| Custom Resources (kind) | Amazon AWS | Google GCP | Kubernetes/Openshift |
| Postgres | RDS | GCP cloud SQL | Postgres |
| PostgresSnapshot | RDS snapshot | Cloud SQL Backups | N/A |
| Redis | Elasticache | GCP Memory Store | Redis |
| RedisSnapshot | Elasticache snapshot | RDB snapshots | N/A |
| BlobStorage | S3 bucket | N/A | N/A |
This operator watches five kinds created by the CRD, listed in Table 2.1. These CRD kinds all adhere to Kubernetes object standards and have the following schema:
-
apiVersion: The version of the API
-
kind: The name of the kind in the Kubernetes API
-
metadata: Contains information you can add, like the names of the instances of the kind, the namespace, labels, annotations, and finalizers. It will also contain fields generated automatically by the Kubernetes API such as uid, creationTimestamp, generation, and managedFields. These are common fields in Kubernetes for all kinds.
-
spec: The specification, the desired state for the kind to be in. Operators act upon the values contained in the spec. The cloud resources operators fields in the spec are as follows
-
secretRef: The location where we want the database connection and credentials stored.
-
tier: Tier specifies the size of the database. The tier can have a value of either “production” or “development”. Where development will install a smaller database.
-
type is where the database will be installed. There are three types that determine the provider: managed=AWS; workshop=Kubernetes (particularly an Openshift version of Kubernetes); and GCP=Google Cloud.
-
maintenanceWindow: Can be set to a day and hour you want to turn on the maintenance period on your cloud storage.
-
-
status: The operator creates and updates the status fields when a kind has been acted upon. The cloud resources operator’s status has 6 fields listed below.
-
message: Information from the cloud provider on the current state of the database install
-
phase: The operator’s current mode of operation: “in progress,” “deletion in progress,” or “completed”
-
provider: Confirms the type of database provisioned
-
secretRef: Confirms the location where the database connection and credentials have been stored
-
strategy: Confirms the cloud provider used
-
version: The engine version of the database installed.
-
Let’s create a Postgres CR for the Cloud-Resources-Operator; we can do this with the kubectl apply command, as in Listing 2.2. We will pass in CR information using the end-of-file (EOF) functionality, which creates the CR’s YAML with a single command. Notice that the user doesn’t create the status. The status that will be added by the operator
Listing 2.2 Cloud Resources Operator Sample Postgres CR
$ kubectl apply -f - <<EOF---apiVersion: integreatly.org/v1alpha1kind: PostgresMetadata: name: example-postgres Namespace: example-namespace labels: productName: productNamespec: secretRef: # A name: secret-name namespace: example-namespace tier: development # B type: managed # C maintenanceWindow: false # DEOF#A secretRef which is the name and namespace of where we want the Postgres connection and credentials stored.
#B t_ier_ determines the size of the RDS Postgres instance spun up on AWS.
#C t_ype_ will select where we want the Postgresql database provisioned in this case, it’s AWS.
#D maintenanceWindow is disabled in this case so we won’t set a maintenance window.
The operator watches for an API kind defined by a CRD. An instance of one of that kind is a Postgres CR. The operator acts upon the Postgres CR and starts to generate the PostgreSQL database on AWS. After a while, The status will be added to the custom resource. The status will continue to update until it has reached a state that satisfies the specification. We can see the current state of the status in the Postgres CR with the kubectl command in Listing 2.3.
Listing 2.3 Postgres CR after the Operator has finished acting upon it
$ kubectl get postgres example-postgres -n example-namespace -oyaml | grep -A 10 “status:”status: message: >- # A rds instance aws-instance-name is as expected, aws rds status is available phase: complete # B provider: aws-rds # C secretRef: # D name: secret-name namespace: example-namespace strategy: aws # E version: '13.8' # F#A message gives us a message directly back from the AWS API with the ID of the cluster.
#B phase is completed so the database install is completed.
#C provider returns the type of database provisioned in this case “aws-rds”.
#D secretRef confirms that the secret was created in the desired namespace with the correct name.
#E strategy __confirms the cloud provider used in this case “aws”.
#F version returns the engine version for the Postgresql database.
As we can see, the CR adheres to the five blocks defined earlier. ApiVersion is the version we defined in our CRD for the Postgres kind. The metadata identifies the name and namespace of the kind. The spec is in all Kubernetes objects, but generally, the operator’s custom logic acts upon the data contained within the spec.
Status is part of all Kubernetes objects. In this case, the operator has customized the Status and is updating it with the current state of the RDS provision on AWS. As the operator detects a CR, the status block in the CR will be generated automatically by the operator, and the operator will update it.
2.3 Getting your hands dirty building an operator
In the previous sections, we discussed existing operators and their various use cases. We followed up with a deep dive into the Cloud Resources operator, which showed how operators can extend functionality beyond the Kubernetes API. Now that we are a bit more familiar with operators and their capabilities, we can begin to get our hands dirty with them. We will begin by defining our use case. Later, we will get into the nuts and bolts of building an operator.
Let’s say we have a Git repository with a deployment specification in YAML for an application. We want this deployment to update on the cluster every time we push changes to the deployment in the Git repository. So we want the Kubernetes API to act on something that happens off-cluster in a Git repository and results in an update to deployment on the cluster. To achieve this, we can write an operator to leverage Git and the Kubernetes API. The operator will pull the YAML file, create a Deployment resource in the Kubernetes cluster, and update the status in the Kubernetes resource configuration. The pattern of synchronizing your configuration with a Git repository is called GitOps. We can start building an operator that follows the principles of GitOps, as shown in Figure 2.6.
Figure 2.6. Pull-based deployment
To keep it simple, the GitOps Operator will pull the YAML from a public repository and create the deployment in the Kubernetes cluster. A GitOps operator like ArgoCD, for example, can do more. This operator will observe the resource’s state and report the status by updating the YAML. We can start with writing a simple form of the GitOps Operator and help you go over the operator concepts with a practical approach.
2.3.1 Writing the GitOps Operator
The GitOps Operator is a piece of software on Kubernetes that acts as a bridge between the Git repository and the deployed system, ensuring that the system is always in the desired state. The desired state for the operator is to create the Kubernetes resources for the given git repository code if it contains the Kubernetes specifications.
First, we need a way to define the public URL for the code repository in the form of a Custom Resource. We will use the CRD endpoint to add a new Resource type in Kubernetes. The CRD is the core building block for extending the Kubernetes API and defining your required resource type. The CRD allows you to specify the schema for the resource you want to add as part of the Kubernetes API. For creating a CRD, we will leverage the operator tools to determine the model in the preferred programming language and convert the model into a Kubernetes YAML specification. We will learn about CRDs and how to define them in later sections.
Next comes defining the desired state of your system in a declarative configuration file, such as a CR. Custom resources are instances of a kind in the Custom Resource Definitions. For the GitOps Operator, we need to specify the URL containing the Kubernetes Deployment specification in YAML format for a sample application.
A custom controller will observe the Custom Resource configuration file. In our example, the GitOps custom controller will monitor the Git repository and compare the system’s current state to the desired state specified in the configuration file.
The GitOps Operator, as shown in Figure 2.7, will create the resources in Kubernetes contained in the Git repository and ensure they stay in the desired state by making any necessary updates.
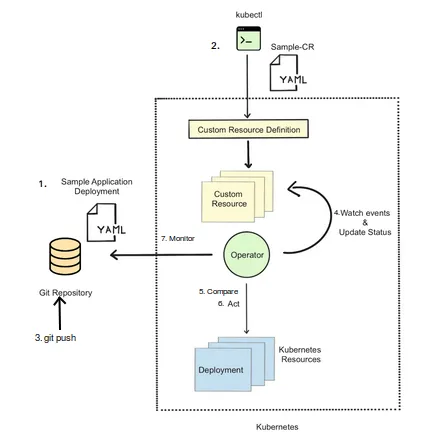
Figure 2.7. GitOps Operator Overview
We will go through each step in detail and implement the GitOps Operator in the rest of the chapter. Before we look into the implementation, let’s review how the operator will work:
-
We have a sample Git repository that contains a sample application with Kubernetes deployment specifications in YAML format.
-
A developer first creates a resource configuration (a Custom Resource of kind GitOps) in Kubernetes for the GitOps Operator containing the URL of the Git repository.
-
A developer pushed code changes to the sample application YAML file in the Git repository.
-
The GitOps Operator detects the changes and retrieves the updated YAML file containing the deployment specifications from the repository.
-
The operator compares the system’s current state in the Kubernetes cluster to the desired state specified in the resource configuration file.
-
If the current state does not match the desired state, the operator makes the necessary updates to bring the system into the desired state.
-
The operator continues to monitor the Git repository and the system, ensuring that the system stays in the desired state.
Writing the GitOps Operator will require choosing a programming language and framework for your operator. Kubernetes client libraries are available in all popular languages.
Some popular options are
-
Operator SDK (https://sdk.operatorframework.io)
-
Kubebuilder (https://github.com/kubernetes-sigs/kubebuilder)
-
Java Operator SDK (https://javaoperatorsdk.io)
-
Metacontroller (https://metacontroller.github.io/metacontroller/intro.html)
You can use any tool and framework suitable for the use case and your preferred programming language. The process for writing any operator will be similar. You could generate the GitOps Operator project using the Operator SDK and the Quarkus plugin for Java, which is a cloud-native Java framework. To generate operators with Golang, use plugins like go/v3. The Operator SDK also supports creating operators using Ansible and Helm. This chapter will use the Java Operator SDK and the Fabric8 Java client, __which is a Java client for Kubernetes, to showcase the GitOps operator and operator concepts.
Generating operators in Java
The first step in generating an operator is to create an empty directory where the operator boilerplate will be placed. Create a directory with the name java-operator-ex.
$ mkdir java-operator-exNext, we use the Operator SDK with the Quarkus plugin to generate base boilerplate code for the GitOps Operator. The domain parameter can be thought of as a namespace and should be a well-formed domain name unique to you or your organization. In the case of the generated Java project, the domain will be reversed and used as the package name for the source code.
$ operator-sdk init --plugins quarkus --domain k8soperators.github.com --project-name java-operator-exThe java-opeator-ex code can be found at https://github.com/k8soperators/examples/tree/main/code/java-operator-ex.
Generating the custom API for the operator
Now, we can generate a scaffold for adding the Custom Resource Definition of kind GitOps. The operator-sdk create api command will generate the API schema in the preferred programming language based on the plugin type. The command takes Group, Version, and Kind (GVK) as input for the custom resource we want to add and generates the boilerplate code for the base API schema. Creating an API with an existing internal Kubernetes group, such as apps or admissionregistration.k8s.io should be avoided.
$ operator-sdk create api --plugins quarkus --group com.github.k8soperators --version v1alpha1 --kind GitOpsThe operator-sdk create api command will generate the boilerplate code for defining Spec and Status models for the GitOps object. We have seen in Chapter 1 about the Kubernetes Objects and top-level fields consisting of Spec and Status. You can add custom fields in the Spec and Status for the GitOps API schema.
2.3.2 Defining a custom resource in Java
The Java Operator SDK provides additional tools that enable developers to define custom resources and controllers. Custom resources will be defined in data structures specific to the language being used. In this example, we will define the GitOps custom resource using plain old Java objects (POJOs) to get started.
The two primary classes that must be defined are specification (spec) and status. For example, the Pod resource in Kubernetes uses the spec to define the desired state such as the containers, and the status to report on the actual state, such as the phase. As seen in Listing 2.4, our specification for the GitOps custom resource has a single property: the remote resource URL.
Listing 2.4 GitOps Java Specification Class
public class GitOpsSpec { #A String url; #B}#A Top-level class representing the model of the specification for the custom resource
#B URL for the remote resources to be created in the cluster
For brevity, Listing 2.5 (and others) omit the typical Java getter and setter methods. The status, as shown in Listing 2.5, includes a phase to indicate whether the resources were successfully applied to the cluster and a message to contain error details if a failure occurs.
Listing 2.5 GitOps Java Status Class
public class GitOpsStatus { #A public enum Phase { #B UNKNOWN, READY, FAILED; } public static class GitOpsResource { #C String apiVersion; String kind; String name; // methods omitted } Phase phase; String message; Set<GitOpsResource> resources; #D}#A Top-level class representing the model of the status section of the custom resource
#B Enumeration of possible values for the phase of the status
#C Class to hold the information for a single resource that has been created from the CR
#D Set of all resources actually created from the CR
The status’s phase in Listing 2.5 is defined as a Java enum to show that there are three possible values for that property. Additionally, the status includes the set of resources that were found via the spec’s URL and created or updated in the cluster.
Finally, these classes are assembled using a subclass of the generic Fabric8 CustomResource which provides additional properties such as kind, apiVersion, and metadata. Since CustomResource is generic, the GitOpsSpec and GitOpsStatus types are given as type parameters in Listing 2.6. The spec and status properties are then available using getters and setters defined by CustomResource. We define the top-level class incorporating the spec and the status classes. This class has a Namespace interface that indicates that the CRD instances are created using namespace scope, i.e. they will not be cluster scoped.
Listing 2.6 GitOps Java CustomResource Classes
@Group("com.github.k8soperators") #A@Version("v1alpha1") #B@JsonInclude(JsonInclude.Include.NON_NULL)public class GitOps extends CustomResource<GitOpsSpec,GitOpsStatus> implements Namespaced #C{ private static final long serialVersionUID = 1L;}#A API group for the custom resource definition
#B API version
#C Top-level class incorporating the spec and status classes.
The YAML custom resource definitions (CRDs) will be generated by running the $ mvn package command in the project root.
The output YAML will be placed in the target/kubernetes directory. Behind the scenes, the operator tooling will generate the GitOps CRD in YAML format using the GitOpsSpec and GitOpsStatus, as shown in Figure 2.8
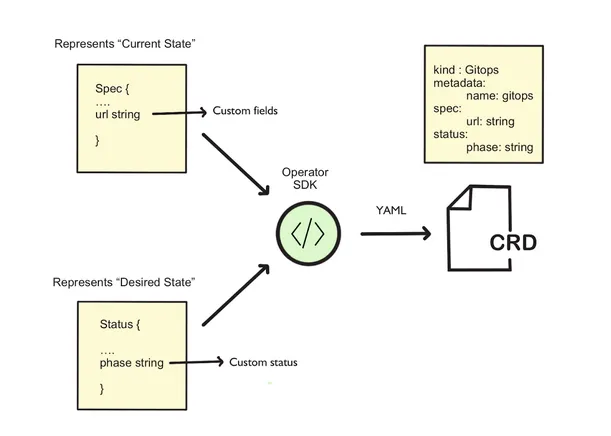
Figure 2.8. Generating the GitOps CRD from a model defined in the programming language
Now we have seen how to create CRDs and a CR. For the GitOps Operator, the GitOps CRD will extend the Kubernetes API and allow configuring the public Git URL using a CR of the kind ‘GitOps’. Kubernetes’s persistent layer stores resources like CRDs and CRs, but data plane resources still need to be scheduled. These custom resources will also need a custom controller, which we will configure in Section 2.4. Our operator will pull the content from the URL and try to create the resources.
2.3.3 Understand custom resource definitions to extend the Kubernetes API
The Custom Resource Definition, as the name suggests, is the “Definition” of a Custom Resource. The definition implies that the custom-added resource follows a standard Kubernetes resources structure. Once the Resource type is added, you can create a new instance known as Custom Resources, similar to creating a new instance of any native resource in Kubernetes like Deployment, Service, or ConfigMap.
For the GitOps Operator scenario, we can define a CRD with the resource kind GitOps and a field url as a string type, as shown in Figure 2.9. The GitOps Operator will allow developers to create a CR in any namespace with the field “url” to specify the code repository. If the “url” has the Kubernetes deployment specifications, the operator will create the corresponding Kubernetes Resources.
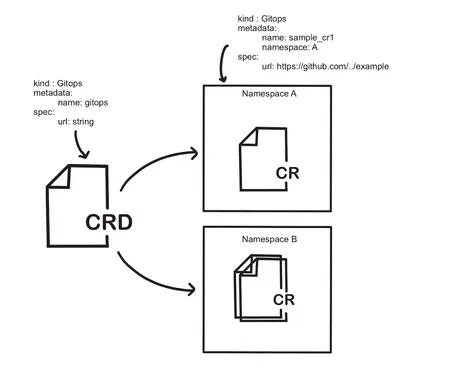
Figure 2.9. CRD and CR Representation
Before we define a CRD and CR for the GitOps Operator, we can look into how the Kubernetes API server determines the CRD schema. If you recall concepts like Group, Version, Resources, and Kind from Chapter 1. We can review GVR and GVK for the CRD in Kubernetes, and Listing 2.7 shows the CRD as a REST end-point in Kubernetes.
Listing 2.7 Custom Resource Definition API schema
$ kubectl get --raw /apis/apiextensions.k8s.io/v1/ #A{ "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "apiextensions.k8s.io/v1", "resources": [{ "name": "customresourcedefinitions", #B "singularName": "", "namespaced": false, #C "kind": "CustomResourceDefinition", #D "verbs": [ #E "create", "delete", …], "shortNames": ["crd", "crds"],#F}#A kubectl get command to fetch API extension group resources
#B Resource name for the Custom Resource Definition
#C Cluster Scope resource
#D Kind name CustomResourceDefinition
#E Operations allowed for the Custom Resource Definition resource
#F Short name references like CRD: singular and CRDs: plural.
The CRD endpoint allows the management of custom resources. The added custom resource will have the same structure as a Kubernetes object and have the top-level standard fields such as apiVersion, kind, metadata, spec, and status. Once we add a Custom Resource Definition, it is available for the entire Kubernetes cluster. Instances CR created using the CRD can be namespace-scope or cluster-scope level. We have seen how the CRD and CR can be created for the GitOps Operator.
First, we can review the CRD for our GitOps Operator, as shown in Listing 2.8.
Listing 2.8 GitOps CRD
cat gitops.com.github.k8soperators.v1.ymlapiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinition #Ametadata: name: gitops.com.github.k8soperators #Bspec: group: com.github.k8soperators #C names: kind: GitOps #D … scope: Namespaced #E versions: - name: v1alpha1 #F schema: openAPIV3Schema: properties: spec: #G properties: url: #H type: string type: object status: #I type: object properties: phase: type: string enum: #J - READY - UNKNOWN - FAILED message: type: string resources: #K type: array items: type: object properties: apiVersion: type: string name: type: string kind: type: string…#A Top level Kind represents the CRD type resource
#B Name of the custom resource type, i.e. GitOps
#C Group for the custom resource type
#D Represents the added Object type
#E Scope for the instances of GitOps type
#F Version for the custom resource type
#G Custom fields are added under spec
#H field url added as string type allow configuring the git repository
#I Custom status fields added under the status
#J Custom status field `phase` only allows value to set from the enum.
#K Array that contains the set of resources created in the cluster from the spec’s URL
Adding the CRD will be similar to creating any native Kubernetes Resources. We can use the kubectl tool for creating the CRD.
Create the GitOps CRD
$ kubectl apply -f sample_gitops.yamlThe GitOps CRD is exposed as a Kubernetes API. Now GitOps has become an integral part of Kubernetes Resources, which means all allowed standard operations on the native resources can also be performed on the GitOps resources. For example, we can use the kubectl get operation on the GitOps Resources, as shown in Listing 2.9.
Listing 2.9 GitOps API
$ kubectl get --raw /apis/gitops.com.github.k8soperators/v1alpha1{ "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "gitops.com.github.k8soperators/v1alpha1", #A "resources": [ { "name": "gitops", #B "singularName": "gitops", "namespaced": true, "kind": "GitOps", #C "verbs": [ #D "delete", "get", … ],}#A API group for the GitOps resource type
#B API Resource name
#C Kubernetes Object name for the resource gitops
#D Permitted verbs for the GitOps resources
One thing to notice in the GitOps CRD: the field "namespaced" is set to “true”, which means resources are created at the namespace level. Suppose you want developers to create individual deployments in separate namespaces; set the scope to namespace level. But if you want instances created that are reusable for an entire Kubernetes cluster, set the scope to cluster level. Later, we will learn how to set the scope level for the resources and design the cluster scope operator.
We can create a GitOps CR with the URL pointing to a Kubernetes resource specification YAML in the default namespace.
Creating a CR (instance of GitOps)
$ kubectl apply -f config/samples/k8soperator_v1alpha1_ghops.yaml
We can review the created sample CR, as shown in Listing 2.10.
Listing 2.10 Get the GitOps CR
$ kubectl get gitops.com.github.k8soperators gitops-sample -o yamlapiVersion: gitops.com.github.k8soperators/v1alpha1kind: GitOps #Ametadata: … name: gitops-sample #B namespace: default #Cspec: url: https://raw.githubusercontent.com/k8soperators/sample-yamls/main/kubernetes-quickstart/src/kubernetes/kind.yml #D#A Kubernetes object type for the GitOps
#B User given name for CR
#C Namespace in which the operator will manage the gitops resources
#D Url configured for the sample application pointing to Deployment template
Developers can create one or more instances per namespace of the GitOps type with any URL pointing to a valid Kubernetes specification. After creating a CR, you won’t see any new resources scheduled in the same namespace. The CRD states the definition, and the CR declares the user’s intent, but taking action requires a Controller. Kubernetes’s in-built controllers only manage native resources. For the GitOps resource type, we need a Custom Controller to observe the GitOps CR and take action to create the resources specified in the url field.
2.4 Adding a controller for the GitOps API
Once the custom resources have been defined, starting with Java objects, and applied to the Kubernetes cluster as CRDs, we can begin to look at the business logic that needs to be written to actually apply the GitOps resources to the cluster. As we’ve discussed, the primary responsibilities of an operator are to watch the custom resource(s), compare their desired state to the actual state of the cluster, and act by updating the cluster to come closer to the desired state. In the context of an operator, the act of updating the cluster resources based on the desired state is referred to as reconciliation or reconciling. Figure 2.10 demonstrates the operator’s relationship to the custom resources and the Kubernetes resource it manages.
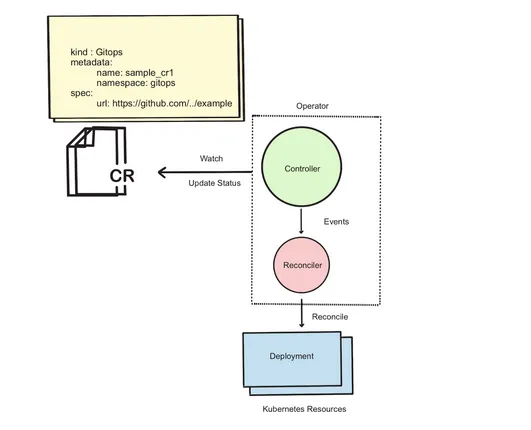
Figure 2.10. GitOps Controller & Reconciler operating on the Sample CR
In addition to providing a way to generate custom resource definitions, the Java Operator SDK also provides interfaces that can be implemented to provide the reconciliation functionality of the operator. Listing 2.11 shows the skeleton of the GitOps Operator. The ControllerConfiguration directs the Java Operator SDK to configure the operator to only watch for GitOps resources in the same namespace as the operator deployment. The generic Reconciler interface allows us to implement a type-safe reconcile method that will be called for each change to any watched GitOps custom resource. The reconcile method will allow our operator to obtain the desired state (via the resource’s url) and the current state in the cluster to determine if any changes to the current state are necessary.
To interact with the Kubernetes cluster, the reconcile method will also need access to a Kubernetes client. Since the example project is developed with Quarkus, we are able to have a client provided by the framework set in the client field in the controller object.
Listing 2.11 Reconciler class and reconcile method
@ControllerConfiguration(namespaces = WATCH_CURRENT_NAMESPACE)public class GitOpsReconciler implements Reconciler<GitOps> { # A private final KubernetesClient client; # B
public GitOpsReconciler(KubernetesClient client) { this.client = client; }
@Override public UpdateControl<GitOps> reconcile(GitOps resource, Context<GitOps> context) { #C … }}#A GitOpsReconciler class that implements the Java Operator SDK’s Reconciler generic type. Indicates that instances of this class will operate on instances of the GitOps custom resource
#B Kubernetes client that will be used by the reconcile method to create or update the Kubernetes resources present in the CR specification’s URL
#C Reconcile method called by the Java Operator SDK when a GitOps resource is added or modified in the cluster
Before we dive into the code of the reconcile method, we should consider what information we have in the GitOps resource and how we can use it to update the other resources in the cluster. As shown previously, the spec block of the GitOps CR contains only a URL to a file that may contain one or more Kubernetes resources. The reconcile method will need to fetch the URL and parse it into an in-memory representation. Finally, each resource should be created in Kubernetes, or replaced if it already exists. To keep things simple for now, the reconciliation process will not yet be capable of deleting resources that were present in earlier versions of the file referenced by GitOps’s URL attribute.
Listing 2.12 Fetch the Resource via URL and apply resources
URL downloadURL = URI.create(resource.getSpec().getUrl()).toURL();List<HasMetadata> desiredResources;
try (InputStream source = downloadURL.openStream()) { # A desiredResources = client.load(source) .get() .stream() .map(res -> setOwner(res, resource)) # B .collect(Collectors.toList());}Set<GitOpsResource> resources = desiredResources.stream() .map(client::resource) .map(Applicable::createOrReplace) .map(rsrc -> new GitOpsResource( rsrc.getApiVersion(), rsrc.getKind(), rsrc.getMetadata().getName())) .collect(Collectors.toCollection(LinkedHashSet<GitOpsResource>::new)); # C#A Retrieve the data stream specified by the spec’s URL attribute
#B Set the GitOps CR as the owner of each created or updated resource
#C Apply the new or changed resource to the Kubernetes cluster, creating a set of GitOpsResources for use in the status
In Listing 2.12, the reconcile method invoked a `setOwner method for each of the resources discovered at the remote URL. Listing 2.13 shows the details of this process. The purpose of setting the GitOps resource as the owner of each newly-created or updated resource is to establish a relationship between the two. The owned resources are subordinate to the primary resource, in our case, a GitOps resource. If the owning GitOps resource were to be deleted, Kubernetes would see this relationship and know that the subordinate resources also should be deleted. In this way, the GitOps resources are a representation of all of the resources created from its specification’s URL.
Listing 2.13 Setting the GitOps resource as owner on each resource
HasMetadata setOwner(HasMetadata resource, GitOps owner) { resource.getMetadata() .setOwnerReferences(List.of(new OwnerReferenceBuilder() #A .withKind(owner.getKind()) .withApiVersion(owner.getApiVersion()) .withName(owner.getMetadata().getName()) .withUid(owner.getMetadata().getUid()) .build())); return resource;}#A Set the owner of each resource to be the GitOps resource. This establishes a link between the two resources within Kubernetes
The penultimate step of the reconcile method is to update the status section of the GitOps resource to indicate whether the application of the spec’s URL resources succeeded or failed. Listing 2.14 shows that one of two possibilities may take place. When everything is applied without exception, the process will set the phase to READY and remove any previously-set status message. Otherwise, when exceptions occur, the phase will be set to FAILED, and the type and message of the exception will be placed in the status’s message.
Finally, reconcile will return an UpdateControl object that wraps the GitOps resource and also indicates to the Java Operator SDK that the status of the resource in Kubernetes should be updated using a PATCH operation.
Listing 2.14 Updating the GitOps resource status
@Overridepublic UpdateControl<GitOps> reconcile(GitOps resource, Context<GitOps> context) { GitOpsStatus status = getOrCreateStatus(resource); #A
try { // Code to fetch data via URL, see listing 2.12 above status.setPhase(GitOpsStatus.Phase.READY); #B status.setMessage(""); status.setResources(resources); } catch (IOException e) { status.setPhase(GitOpsStatus.Phase.FAILED); #C status.setMessage(e.getClass().getName() + ": " + e.getMessage()); }
return UpdateControl.patchStatus(resource);}#A Retrieve the status object from the CR, or create it if none has yet been set
#B Mark the status as READY when no exceptions occur in processing the CR spec’s URL
#C Mark the status as FAILED when an exception occurs, including the exception type and message
So far, we have seen how to define a custom resource in Kubernetes. We have also seen how to create the GitOps reconciler, which will fetch the deployment specification from the git repository and create the corresponding deployment resource on the Kubernetes cluster. Once the above actions have taken place, we have seen how we can use the operator to update the status block of the custom resource with the result of the actions. This helps clarify whether the deployment is successful or not. In case of failure, the Reconciler retries to create the resources in the next iteration with a periodic resync loop. Let’s try deploying the GitOps Operator and see what we have learned so far.
2.5 Summary
-
Operators provide a simple way to extend Kubernetes to include resources beyond those running in Kubernetes itself. They are rapidly becoming a default installation and upgrade method for many types of software running in Kubernetes.
-
The Red Hat Cloud Resources operator is an example of an operator that extends Kubernetes by provisioning external resources such as databases, caches, and other storage hosted by cloud providers like AWS and Google.
-
Resources outside the Kubernetes cluster can also drive operators. An example is an operator that deploys resources to the cluster that are stored and managed in a remote git repository, following a GitOps approach.
-
The primary functions of an operator are to watch custom resource(s), compare them to the actual state of the cluster, and update the cluster to move it closer to the desired state. This process is known as reconciliation.
-
The advantage of using the operator pattern is that it helps to abstract away the need for in-depth Kubernetes knowledge in complex Kubernetes installations.
-
The Operator SDK is easily interchangeable for use with different programming languages and frameworks for generating an operator.
-
CRD are always available at the cluster level as they are an extension of the Kubernetes API, but the operator and the custom resources can be namespace scoped
-
A good way to think of operators, is as like a controller for Custom resource.